前六篇之后,我们对curl的基本使用已经有了一定的了解。下面我们就在实际场景中使用我们的所学。
本篇实例目标为编写linux脚本,使用curl完成发布文章至百度空间。
下文将从百度空间登陆到发表文章,对每个过程的HTTP进行分析,并编写脚本实现。
工欲善其事,必先利其器
抓包分析我们使用chrome自带的Developer Tools。
实际分析过程中最好把Developer Tools的Network标签左下角的“Preserve Log upon Navigation”选中,如下图圈中处:
单击变为红色即可。
此选项的作用在于当当前页面跳转到其他网页时,保存原来的日志记录。
默认不保存,比如在登陆成功一个网站后,自动跳转到其他网页,这样登陆网站过程中的记录都不保存。我们就没有办法对登陆过程进行具体分析。
POST登陆
1. 操作过程
登陆我们采用网址https://passport.baidu.com/?login,而不使用网址http://hi.baidu.com/index.htm或http://hi.baidu.com/go/login 右侧的登陆框。
这是因为后者可能因为百度空间改版等原因改变,而前者是百度账号的登陆界面,变化的几率要小。而且后者界面很多图片等元素,不利于我们抓包分析。
2. 登陆过程分析
登陆成功后找到/?login的POST包,如下图: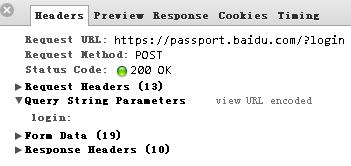
主要显示了状态信息、请求头部(Request Headers)、POST数据(Form Data)和响应头部(Response Heades)。
Query String Parameters是对GET的参数的解析,即网址中的?login。一般网址中“?”后面的都应该是参数,具体请参考Linux下cURL使用教程之二:HTTP协议概述中“GET命令”一节。
请求头部如下(view source模式):
POST /?login HTTP/1.1 Host: passport.baidu.com Connection: keep-alive Content-Length: 215 Cache-Control: max-age=0 Origin: https://passport.baidu.com User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.168 Safari/535.19 Content-Type: application/x-www-form-urlencoded Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Referer: https://passport.baidu.com/?login Accept-Encoding: gzip,deflate,sdch Accept-Language: zh-CN,zh;q=0.8 Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3 Cookie: BAIDU_WISE_UID=...无关cookie代码,很长,略去 |
POST数据如下(view decoded模式,因为curl可以完成urlencode,我们发送明文即可):
tpl_ok: |
3. 登陆过程curl脚本
百度要求的不严格,因此我们不考虑来源页面(Referer)等信息,只注意隐藏User-Agent字段。同时保存cookie供后续使用。脚本如下:
curl -s -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -o baidu001.html -D bdcookie001.txt \ |
实验发现其他字段非必要,因此舍弃。
POST发表文章
1. 操作过程
点击“我的空间”,进入http://hi.baidu.com/home,然后点击“文字“,进入到`http://hi.baidu.com/pub/show/createtext`,随便写些内容,右侧加些标签,发表即可。
2. 过程分析
找到对createtext的POST包。POST的url为http://hi.baidu.com/pub/submit/createtext。
请求头中没有我们关心的字段:cookie不用具体分析,Referer等字段我们不去关注。
POST数据如下:
title: Stackeye's title |
title是文章标题,tags是标签,content是内容。
除此之外还有一个bdstoken字段猜不出其含义。多次测试发现,其他字段基本固定,而bdstoken字段在每次退出重新登陆后就会发生变化。
这种字段来源有三种可能性:
- 此字段没有实际意义
比如只是个简单的标志,服务器端并不校验此字段值。 - 服务器生成,然后在POST之前传给客户端
需要我们分析POST之前数据包的响应数据。因为可能的数据包不多(一般来讲,图片、css、js等的包可以直接排除)。 - POST之前的某个网页动态生成
比如此网页或之前的某个网页上的js、Ajax等在客户端执行的函数生成。
这个需要审视此网页和之前的每个网页中的js等代码,甚至需要动态调试,比较麻烦。因此我们最后考虑这种情况。
3. 寻找bdstoken字段
编写脚本,bdstoken传递格式类似的随机值,文章发表失败。
寻找之前的数据包,我们从后向前找,查找每个text/html等网页类型的数据包的Response内容。
Developer Tools的搜索功能搜索不到,可以右键数据包”save all as har“保存为har文件,用记事本打开即可查找。但是不能批量保存,比较繁琐。
更简单的解决方式是使用wireshark抓包,wireshark的字符串搜索可以搜索到。
我们很快找到在GET的createtext页面(http://hi.baidu.com/pub/show/createtext)里有bdstoken字段,GET及bdstoken取出语句:
#get bdstoken |
脚本中使用了awk用于从html代码中提取bdstoken字段,HTML中相关内容为:
<a href="https://passport.baidu.com?logout&bdstoken=393d8ef656bf74c8f739aa3ae5262f94&u=http://hi.baidu.com/pub/show/createtext">退出</a> |
“bdstoken=”作为前分割标志,“&”作为结束标志即可。
4. curl脚本
POST过程
使用的cookie是第一版步产生的bdcookie001
这是因为基本上只有第一步登陆的过程产生重要的cookie信息,其他步产生的cookie是非必须的。title="Stackeye's title"
content="Stackeye's content!<p>This is for curl learning test."
tags="testtags"
curl -s -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -e http://hi.baidu.com/pub/show/createtext \
-o baidu003.html -D bdcookie003.txt -b bdcookie001.txt \
--data-urlencode title="$title" \
--data-urlencode tags[]=$tags \
--data-urlencode content="$content" \
--data-urlencode private=0 \
--data-urlencode imgnum=0 \
--data-urlencode bdstoken=$bdstoken \
--data-urlencode qbid= \
--data-urlencode refer=http://hi.baidu.com/home \
--data-urlencode multimedia[]=:undefined#undefined#undefined#undefined \
--data-urlencode private1=0 \
--data-urlencode qing_request_source= \
http://hi.baidu.com/pub/submit/createtext验证成功与否:
#result
result=`cat baidu003.html |awk -F ": \"" '{print $2}'|awk -F "\"" '{print $1}'`
if [ $result -eq 0 ]
then
echo "Success!"
else
echo "Fail!"
fi资源清理语句:
rm -f baidu001.html baidu002.html baidu003.html
rm -f bdcookie001.txt bdcookie002.txt bdcookie003.txt
注意
1. POST文章时,title、content中不能含有特殊字符
title、content中不能含有双引号不能转义的特殊字符,如$,\,。 单引号不转义除单引号之外的所有特殊字符。而且在title="Stackeye's title"和--data-urlencode title="$title" \两处都使用单引号的会出现错误。 因此如果实际应用的话,还需要另外一个特殊字符替换函数,替换$,\,和双引号。
shell脚本对大批量文字的处理比较繁琐吃力。
因此实际场景中,遇到对文字处理较多的场景,shell脚本+curl的方式只作为测试手段探究原理与逻辑,程序使用Java、PHP、Python、C等更强大的语言实现。
2. 没有错误重试
可以使用如下循环进行错误重试:
#retry after fail |
3. 文件权限
文件中保存有账户密码,记得设置文件属性为700,避免密码泄露。
总结
完整脚本如下:
|