ffjson是一个开源的golang工具库,它能大幅度提高json序列化、反序列化的性能,根据作者数据比标准库快2-3倍。
本文旨在分析ffjson的原理及实现,同时分析了ffjson作者对golang程序进行性能优化的思路。
go中的json为什么慢
json序列化是指将实体类转化成json字符串的过程,而反序列是此过程的逆向操作。
官方提供的标准库是encoding/json。我们可以猜想下标准库是怎么实现的:
- 给出一个struct,如何将其json序列化?最简单的解决办法是逐个字段读取,然后按json格式拼接字符串即可。前提是我们需要知道这个struct的结构。
- 任意给出一个struct,如何json序列化?这时必须首先对struct的内部结构进行探测。
对于动态类型语言,如python这很容易,在python中一切皆为对象,其成员也是对象,其中保持了其类型及成员的信息。给定一个对象,通过方法items()可以轻易得到其全部成员,然后对每个成员调用__str__()方法转化为字符串。
虽然go是静态类型语言,但这个方法在go中也可以实现,通过使用reflect包也可在运行时动态探测到变量的结构,从而对实现序列化。
一个标准库提供的接口,肯定不能只适用于某些struct,而要写出通用的方法,必须要动态识别其成员及类型,然后进行转化。
encoding/json实现
如我们上述分析,标准库具体实现代码如下:
// 对外接口 |
可以看到其中大量使用了interface和reflect,用来遍历struct的所有元素并判断类型。
reflect的效率
可以使用reflect编写demo进行下benchmark,证明reflect的使用会导致程序效率降低。其原因简单概括如下:
- 为了识别struct的结构及字段类型,额外构造了一些数据结构,申请了一些内存空间,即增加了allocation
- 寻找内部成员的时候,算法复杂度是线性的,对于有大量属性或方法的结构,性能下降严重
ffjson原理
由上所述,为了通用使用了reflect导致性能降低。而如果struct都编写对应的序列化处理方法,就不需要使用reflect而导致性能下降了。因为go是静态类型语言且不提供泛型支持,很难找到别的方式。但这样无疑会牺牲代码的通用性。这就需要在性能和通用性之间做出折衷。
一种好的思路就是生成代码:使用通用方法如调用reflect,提前为所有的struct生成好序列化代码。这样只需要在生成的时候使用reflect,而运行时序列化通过使用生成的代码效率得到大幅提高。而代码的生成一般手动执行或在编译时执行,引入reflect导致的性能下降是完全可以忍受的。
通过适当增加编码的复杂度,换取了效率提升:
ffjson works by generating static code for Go’s JSON serialization interfaces.
Protobuf也是使用的这种方案,详见:proto-gen-go。
具体实现
ffjson工作流如下: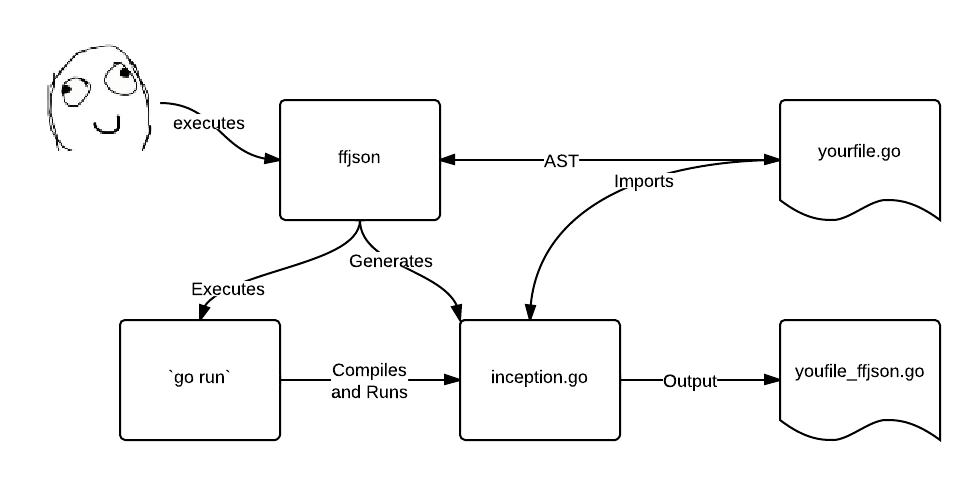
内部实现是动态为指定结构生成MarshalJSON和UnmarshalJSON方法的代码实现。go的encoding/json库中包含两个interface:Marchaler和Unmarshaler,其中分别要求实现MarshalJSON和UnmarshalJSON两个方法。若这两个接口被实现,则会在进行json转化的时候被使用,取代标准库的默认方法。
ffjson在编译时通过调用reflect动态生成代码,而不是在运行时。且部分方法针对gc优化从而大幅提升json操作速度。
使用方法
安装
go get -u github.com/pquerna/ffjson |
每次修改后,需要重新运行ffjson命令生成*_ffjson.go文件。在使用时,通过调用MarshalJSON和UnmarshalJSON实现json的序列化、反序列化。
在结构体定义时,可以指定skip不生成或指定不生成encode/decode方法。
可将ffjson集成进go generate执行。
而可以根据需要选择生成后的文件需不需要维护在代码库中:
- 生成的文件不建议人为修改,随时可以使用ffjson生成。
- 但为了避免对ffjson的依赖,避免不同版本的ffjson可能引入的差异,建议维护在代码库中。
- 对于其在代码库中造成的大量修改,
git diff时可以指定忽略此文件。
Demo
实例代码见:https://github.com/bingostack/ffjson-demo
性能问题
在一些特殊场景下,ffjson无法理解指定类型而无法生成代码时,会回退到使用标准库encoding/json,虽然导致性能下降到未优化的水平,但避免了特殊场景下导致程序出错。
以下场景因为各种原因,会退回至使用encode/json:
- interface成员,只有在运行时才能获得其具体类型,甚至会比直接使用json库慢
- 拥有自定义marshal和unmarshal方法的结构体
- 拥有复杂类型值的map,但简单类型没有问题
- 内嵌结构体类型的结构体的decoder函数
- 切片的切换或map的切片的decoder函数
通过在生成的文件中搜索“Falling back”,可查找到退回使用encode/json的字段。
遇见的问题
ffjson Error: error=Could not find source directory:
出现这个错误的原因是,ffjson执行的对象文件,必须在GOPATH的src目录下,参考
总结
减少reflect使用
虽然很多情况下,无法避免使用reflect。特别是在一些通用的库函数,如orm中,难以避免使用reflect。但reflect对性能的影响确实很大,因此在常用场景下,应尽可能避免使用。
代码生成器的使用
因为go是静态类型语言,且不提供类似C++的泛型支持,而内置的reflect又有性能问题。因此很多情况下,代码生成器是个很好的思路。如sql语句与struct声明语句之间的互转、项目模板代码的生成等。
而go1.4中加入了go generate似乎也肯定了这一点。